proof drop Memory Systems
proof drop #2 — hierarchical memory beats flat search (when you know where to look)
Proof drop #2. Same rule as always: every number here is reproducible from a one-command script, or it’s marked speculative.
This one is the twin of proof drop #1. UFM was a bet on locality in physical memory — keep the hot region on the GPU. FMM is the same bet in semantic memory — search the relevant region of your knowledge, not all of it.
the claim
Does topic-scoped retrieval — “page the relevant region of memory” — beat a flat scan of the whole store, in both latency and recall, as memory grows?
FMM stores items in a topic hierarchy (domain → subtopic).
A flat vector store searches everything. FMM can instead restrict the search to the subtree the
query belongs to. The question is whether that hierarchy actually buys you anything.
the setup
A synthetic corpus in a topic tree — 16 domains × 8 subtopics = 128 leaf clusters. Each query is a known item, perturbed; we compare searching all N items vs. the query’s domain subtree vs. its leaf subtree — plus a misrouted scope (the wrong domain) to keep myself honest. Vectors are synthetic, so this tests the structure, not embedding quality.
the result
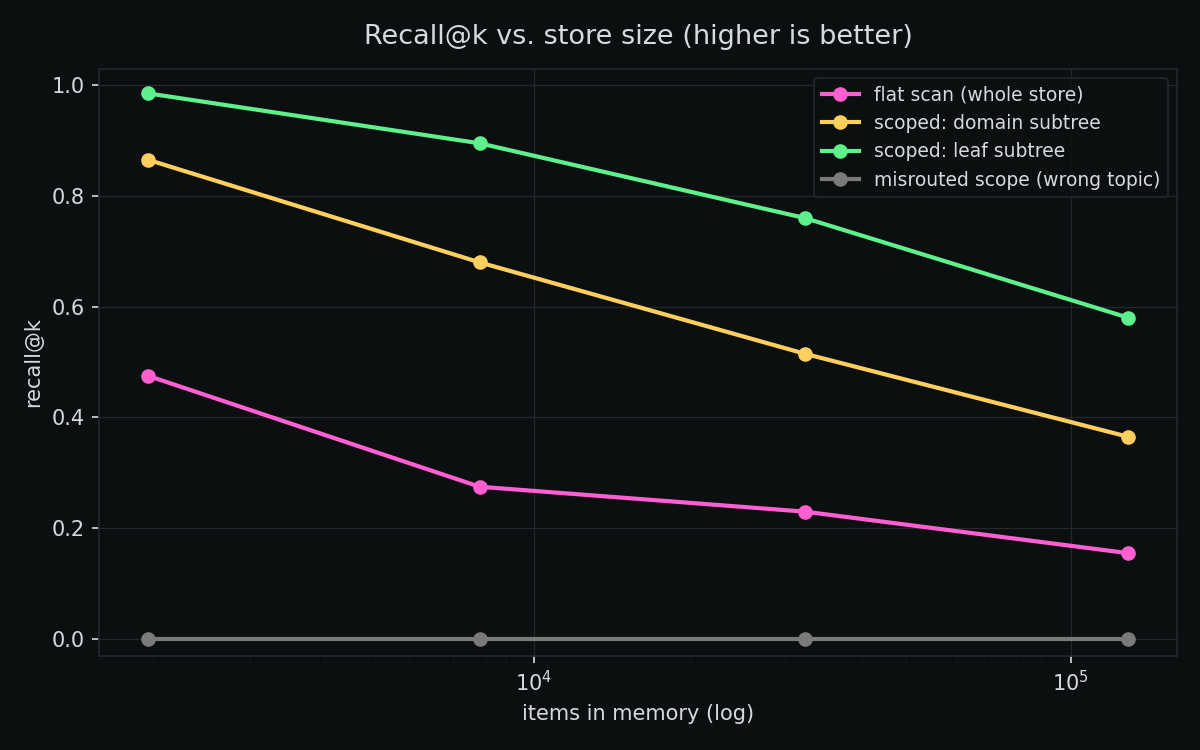
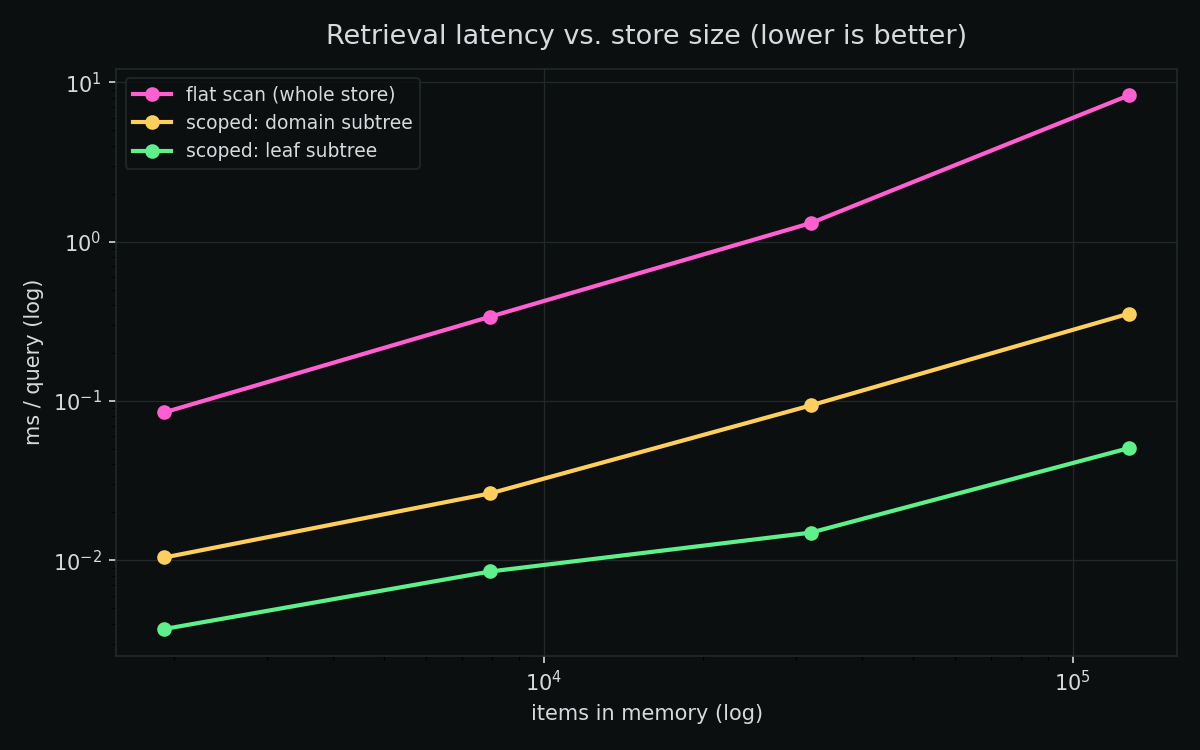
At 128,000 items:
| strategy | searches | latency | recall@k |
|---|---|---|---|
| flat scan | 128,000 | 8.30 ms | 0.155 |
| scoped — domain | 8,000 | 0.35 ms | 0.365 |
| scoped — leaf | 1,000 | 0.05 ms | 0.58 |
| misrouted scope | 8,000 | 0.35 ms | 0.00 |
Two things, and they point the same way:
Flat search gets worse on both axes as memory grows. Latency climbs ~linearly (to 8.3 ms), and — less obvious — recall falls (0.48 → 0.155). The more unrelated topics you pile into one flat index, the more distractors crowd out the thing you actually wanted.
Scoping wins on both axes — ~164× faster and ~3.7× more accurate at 128k. Searching only the relevant subtree is sublinear and removes cross-topic distractors before they can mislead you. Finer scope (leaf) beats coarser scope (domain). Memory that’s organized retrieves better, not just faster.
the honest catch
Look at the gray line: a misrouted scope has recall 0.0. If you search the wrong region, the answer simply isn’t there. Hierarchical memory is a bet on routing locality — it pays only when you can address the right region. Get the address wrong and you’ve confidently searched a place the answer was never in.
That’s the same shape as UFM: locality is a superpower exactly when you have it, and a liability when you don’t. The next proof for this thread is therefore not about retrieval at all — it’s about the router: how reliably can you pick the right scope? A great index behind a bad router is the misrouted line.
reproduce it
git clone https://github.com/Linutesto/fmm && cd fmm
pip install -e ".[torch]" && pip install matplotlib
cd benchmarks && ./run.shIt prints your environment, runs a library correctness check (scoped retrieve really does stay
inside the subtree), and writes every number to results/. Method, full sweep, and limitations
are in the benchmark README.
limitations (so you don’t over-read this)
- Synthetic embeddings — this isolates the structural question. Real embeddings + a learned router are future work; absolute recall will move.
- The defensible claim is the relative advantage and the scaling trend, not a recall number.
- Topic is assumed known at query time; production needs a router, and a bad router = the misrouted line.
Two proof drops, one thesis: capable AI you can own, through memory that organizes itself. Whether it’s VRAM or knowledge, the move is the same — don’t search everything; search the part that matters.
Yan Desbiens — work conducted at Éthiqueia Québec inc. Proof drop #2.