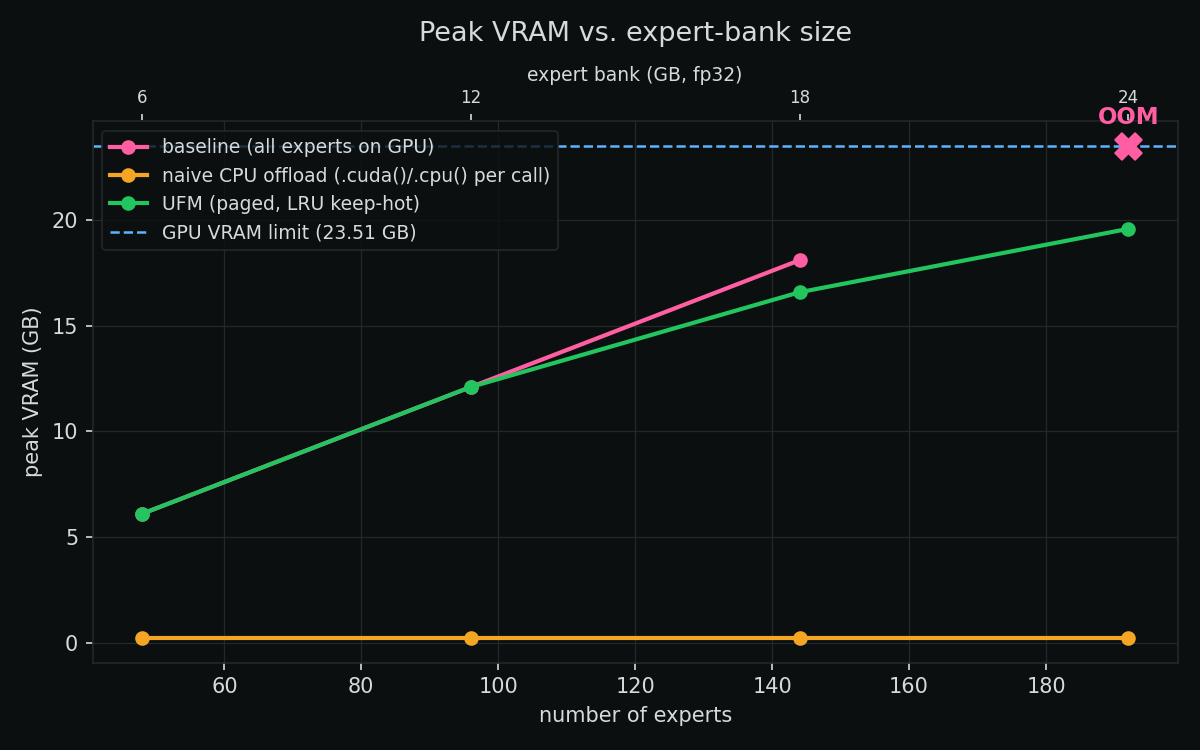
We benchmark Unified Fractal Memory (UFM), a residency manager that treats GPU VRAM and CPU RAM as one elastic pool, on a routed Mixture-of-Experts whose expert bank exceeds device memory. On a 23.5 GB RTX 4090, the standard all-on-GPU placement OOMs at a 24 GB bank; UFM runs the same model holding VRAM at 19.6 GB. When the active working set fits the VRAM budget, UFM matches baseline throughput within ~1% and is ~240x faster than naive per-call CPU offloading; when every expert is touched every step (no locality), UFM is transfer-bound and offers no speedup over naive streaming. UFM is a bet on routing locality, not unbounded memory.
Code + one-command repro · Benchmark report · Figures
{kind=link}
// cite this
reproducible DOI pendingDesbiens, Y. (2026). Unified Fractal Memory: running a routed model larger than VRAM on a single consumer GPU (v0.1.1). Éthiqueia Québec inc.. https://yandesbiens.com/blog/ufm-benchmark/
@misc{desbiens2026ufm,
title = {Unified Fractal Memory: running a routed model larger than VRAM on a single consumer GPU},
author = {Yan Desbiens},
year = {2026},
howpublished = {\url{https://yandesbiens.com/blog/ufm-benchmark/}},
institution = {Éthiqueia Québec inc.},
version = {v0.1.1},
note = {Reproducible benchmark, Éthiqueia Québec inc.},
url = {https://yandesbiens.com/blog/ufm-benchmark/},
}Full citation registry on the citations page. · repository ↗